Wyciek czynników rankingowych Google - analiza pod kątem linków


Wyciek czynników rankingowych Google - analiza pod kątem linków
Jest to wyciek o ogromnej skali - największy jaki kiedykolwiek miał miejsce. Zawiera masę ciekawych informacji, a wiele z nich stawia Google w złym świetle i podważa prawdomówność specjalistów związanych z wyszukiwarką.
Wyciek miał miejsce najprawdopodobniej 13 marca 2024 roku. Do szerokiej publiczności trafił na początku maja. Przeanalizowałem go w całości, algorytm po algorytmie, moduł po module. Żeby nic nie umknęło naszej uwadze.
Czym ten wyciek jest?
Listą ponad 2500 algorytmów dla których opisane jest 14000 modułów, zmiennych, danych dotyczących systemów. Jest tutaj bardzo dużo wiedzy, insiderskiego know-how i Googlowskiej nomenklatury.
Są to czynniki rankingowe dotyczące wyszukiwarki, ale również innych usług Google. Czynniki te są posortowane i opisane. Wiele algorytmów posiada opis swojego działania, jaki jest jego cel. A zarazem…
Czym ten wyciek NIE jest?
Nie jest dokładnym opisem jak algorytmy działają, brakuje tutaj konkretnych wzorów, wag czy korelacji między systemami. Nie wiemy finalnie co jest brane pod uwagę i w jakim stopniu przy serwowaniu wyników.
Wiemy np. że dany system bierze pod uwagę PageRank, ale nie wiemy jak ten jest obliczany, nie wiemy też jaki ma udział w przykładowym systemie. Wiele modułów nie ma opisów w ogóle, albo są zdawkowe, albo napisane w sposób nie pozwalający wyciągnąć jakichś konkretnych wniosków.
Analiza wycieku
Ponad rok temu trafił do nas wyciek Yandexowy, nie tak spektakularny, ale w bardzo podobnej formie. Przeanalizowałem go i spisałem wszystko co istotne w tym miejscu.
Wyciek Yandexowy był konkretniejszy, lepiej i dokładniej opisany. Często wdawał się w szczegóły. Wyciek Googlowy nie jest tak obfity w konkrety.
Mam też problem z niektórymi źródłami anglojęzycznymi, które wyciek obrabiały. Jako, że już dawno nie wierzę ślepo Internetowym rewelacjom, to wszystko co w międzyczasie do mnie dotarło starałem się skonfrontować bezpośrednio z wyciekiem. Niestety, niektóre tezy nie znalazły swojego odzwierciedlenia w pliku źródłowym, albo informacje są na tyle szczątkowe, że wyciągnięte tezy mogą być wesołą twórczością. Wyciek ten jest ważny, bo pozwala skonfrontować kilka powielanych dotychczas mitów. Istotne jest również, aby nie przyłożyć ręki do stworzenia nowych, które będą trawiły branże.
Zresztą w tym miejscu również wyraźnie zaznaczę. Link buildingiem zajmuje się od 10 lat. Przerobiłem większość patentów czy rzetelnych źródeł bezpośrednio od Google i nie tylko, moje know-how to mix teorii i zastosowania jej w praktyce. Jednocześnie tezy tutaj zebrane to mój prywatny punkt widzenia.
PageRank
Czyli metoda nadawania indeksowanym stronom internetowym określonej wartości liczbowej, oznaczającej ich jakość.
To pierwszy algorytm Googlowy, który brał pod uwagę linki zewnętrzne. Patent (US6285999B1) opisujący działanie algorytmu został opublikowany 26 lat temu - w roku ‘98. PageRank napisał historię, wytyczył kierunek działań algorytmu i przy okazji był najgorszym w skutkach algorytmem. Napiszę o tym więcej w swoim czasie.
W Off-site wiemy, że PageRank jest używany po dziś dzień, zresztą Google cyklicznie potwierdzał wykorzystywanie algorytmu.
Ciekawa w tym kontekście jest wypowiedź Johna Mullera, który pisał w 2020 roku, że wykorzystują PageRank, ale formie odbiegającej od oryginału. Pisał, że jest wiele zmiennych.
Może dlatego właśnie w wycieku można znaleźć aż 7 różnych typów PageRank. Niektóre opisane jako eksperymentalne, inne w ogóle:
- PageRank
- PageRank 2
- PageRank 1
- PageRank 0
- PageRank NS
- Raw PageRank
- ToolBar PageRank
A jeszcze ciekawiej się robi, gdy sprawdzimy konkretne konteksty ich użycia:
- PageRank Weight
- FirstCoverage PageRank
- PageRank Score
- Homepage PageRankNS
- Feed PageRank
Co ciekawe, Google wyraża PageRank w sposób liczbowy w skali od 0 do 65535. Co też istotne, odmienne wariacje PageRank są używane w różnych algorytmach. Nie ma jednego uniwersalnego modelu używanego globalnie.
Najważniejsze wnioski
PageRank jest obliczany indywidualnie dla różnych zasobów. Inaczej będzie oceniona strona główna, a inaczej np. kategoria.
W niektórych systemach PageRank jest jasno wskazany jako jeden z kluczowych elementów. Np. w algorytmie PerDocData, który ma za zadanie: zdefiniowanie bufora protokołu używanego zarówno podczas indeksowania, jak i serwowania w ramach infrastruktury wyszukiwania Google. Ten bufor protokołu zawiera różne atrybuty danych dokumentu używane podczas fazy wyszukiwania w celu poprawy i personalizacji wyników wyszukiwania, identyfikacji spamu, zarządzania świeżością dokumentu i wielu innych.
PageRank i wskaźnik autorytetu odgrywają: kluczową rolę w określaniu autorytetu strony i prawdopodobieństwa jej wyższej pozycji w rankingu.
Inny algorytm ResearchScienceSearchSourceUrlDocjoinInfo, który ma za zadanie: zebrać informacje wykorzystywane przez funkcję wyszukiwania Google do zarządzania danymi dokumentów i polepszenia wyników wyszukiwania.
I finalnie doprowadzić do momentu, w którym: Informacje dostarczane przez ten interfejs API mogą wpływać na ranking Google, poprawiając trafność, autorytet i wygodę użytkownika wyników wyszukiwania. W szczególności atrybuty takie jak pagerankNs, title, latestPageUpdateDate, webrefEntity i salientTerms.
Wykorzystuje PageRank, ale jednocześnie sugeruje, żeby go unikać na rzecz PageRankNS (Nearest Seed). No właśnie…
NearestSeeds
To kolejny znany nam dobrze i wykorzystywany w planowaniu działań dla naszych klientów patent Google (US9165040B1). Jest to algorytm, który ocenia wartość danej strony w oparciu o jej umiejscowienie na grafie linków w konkretnych klastrach tematycznych. Jednocześnie określa on “seed pages”, czyli strony kluczowe dla danej kategorii. Im bliżej dana strona znajdzie się Seed’ów i im gęściej się nimi otoczy tym lepszy wynik osiągnie.
Planując kampanię naszym klientom dobieramy portale pod publikacje w taki sposób, żeby pokryć zapotrzebowanie tego algorytmu jak i PageRank. Mówiąc wprost - dla agresywnego przeniesienia mocy wykorzystujemy możliwie najmocniejsze miejscówki karmiąc PageRank. Jednocześnie dla umiejscowienia stron naszych klientów blisko najważniejszych stron w ich klastrach tematycznych wykorzystujemy największe i cieszące się renomą strony tematyczne. Nie dziwi nas więc, że Google łączy te dwa parametry.
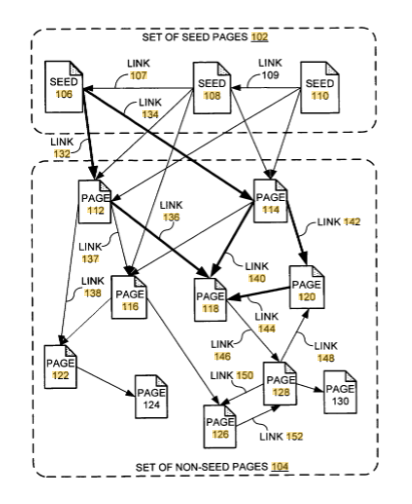
Powyższy graf pochodzi bezpośrednio z patentu Googlowego. Wyobraźmy sobie, że Google nadaje stronom ich PageRank, a następnie opisuje też jaką wartość przenosi dany link.
No właśnie z wycieku dowiedzieliśmy się też, że linki przenoszą różną moc. Wśród modułów znajdziemy PageRank Weight opisany jako: Waga przechowywana w mapach linków dla pagerankera.
I tak np. ze strony seed’u możemy mieć link z ważnego artykułu, który będzie więcej warty niż link, gdzieś głęboko zakopany w strukturze serwisu z archiwalnych zasobów.
Wróćmy do analizy. Co ciekawe, żeby dana strona została Seedem, musi posiadać odpowiednią jakość, która być może jest określana również w oparciu o PageRank. Tutaj dane nie są jasne, ale sugerują taki stan rzeczy.
Algorytm QualityFringeFringeQueryPriorPerDocData, który: definiuje przede wszystkim atrybuty związane z wykrywaniem i przewidywaniem treści fringe. Takie atrybuty mają kluczowe znaczenie w klasyfikowaniu treści i określaniu ich adekwatności i wiarygodności, co może mieć wpływ na pozycję dokumentów w wynikach wyszukiwania Google. Czynniki takie jak podatność na zagrożenia i różne prognozy ryzyka mogą wpływać na ogólną widoczność treści.
Posiada konkrety moduł ProximityScore opisany jako: Wynik w [0, 1] reprezentujący podobieństwo tego dokumentu do znanych "nasion" (seed) podatnych na fringe.
SPAM
Google określa spamowość w dużej mierze za pomocą anchorów. I ma to sens, bo przecież można też spamować z najsolidniejszych miejscówek, unikać oznaczeń artykułów jako sponsorowane, a to skala i wtórność w anchorach jest wtedy trafnym sygnałem o manipulowaniu rankingiem.
Google zwraca uwagę na:
- ile fraz spamowych znaleziono w anchorach wśród unikalnych domen;
- w ciągu ilu dni wykryto 80% tych fraz;
- jaki ułamek wszystkich anchorów stanowią te spamowe;
- całkowitą ilość anchorów;
- datę pierwszego i ostatniego anchora;
- łączną karę i jej czas trwania;
- przewidywane prawdopodobieństwo spamu w oparciu o liczbę naturalnych anchorów.
W tym momencie do gry dołącza Pingwin - nomen omen - cały na biało:
- Linkowane strony główne hosta na tym samym hoście co bieżący docelowy adres URL (zapleczówki?).
- Karę można obniżyć, albo uchronić się przed nią dzięki wcześniej wykorzystywanym anchorom.
- Według anchor quality bucket, anchor z pagerank > 51000 jest najlepszym anchorem. Anchory z pagerank < 47000 są takie same.
Ten ostatni punkt nie jest dla mnie do końca jasny. W jakimś celu Google określa najważniejszy anchor (a może link ogólnie?). Ciekawe.
Google dla ułatwienia obliczeń i rankingu śledzi jedynie 1000 anchorów per domena, a wszystkie powyżej porzuca. Czynnik ten jest ruchomy i zakładam, że zależy od klastra tematycznego. W końcu bez problemu znajdziemy profile linkowe gdzie anchorów jest nawet kilkadziesiąt tysięcy.
Warto też odnotować, że Google tworzy pary URL-Anchor i śledzi konkretną ilość takich par (ok 200), szczególnie w dużych site’ach, gdzie: przez pamięć podręczną może wystąpić podwójne liczenie.
Ograniczona liczba takich par sugeruje, że powinniśmy pilnować trafności anchorów.
Wracam do tego tekstu przed finalną publikacją i jeszcze raz weryfikuję wszystko co związane z “anchorami”. Jakoś nie mogę się pozbyć uczucia, że w nomenklaturze Googlowej Anchor może być niczym innym jak linkiem zewnętrznym, a nie kotwicą samą w sobie.
No bo czym jest “spamowy anchor”? Jakie znaczenie ma “całościowa ilość anchorów”? Czy w końcu: “przewidywane prawdopodobieństwo spamu w oparciu o liczbę naturalnych anchorów.”. Gdybyśmy w całym tym akapicie podmienili frazę Anchor na Link to wszystko nie tylko zachowałoby sens, ale też zyskało na znaczeniu. Taka luźna myśl.
Jakość miejscówek, z których pozyskujemy linki
Google określa jakość stron, z których pozyskujemy linki. Dzieli je na 3 grupy tj. High Quality, Medium Quality i Low Quality.
iPullrank wskazuje, że grupy te są przechowywane w różnych pamięciach: W skrócie, indeks Google jest podzielony na poziomy, w których najważniejsze, regularnie aktualizowane i dostępne treści są przechowywane w pamięci flash. Mniej ważne treści są przechowywane na dyskach półprzewodnikowych, a nieregularnie aktualizowane treści są przechowywane na standardowych dyskach twardych.
Nie mam pojęcia natomiast skąd ten podział - nigdzie nie znalazłem informacji potwierdzających tę tezę. Wygląda na taką wyciągniętą na potrzeby uwierzytelnienia swoich działań. Autor też pozwolił sobie na gloryfikowanie stron newsowych. Wygodnie byłoby tańczyć razem z orkiestrą, ale poczucie obowiązku nie pozwala mi nie wytknąć tej nieścisłości.
Faktem jest natomiast podział na 3 grupy jakościowe. Dokładnie też jest wskazana grupa “news high quality site”, ale również “high quality review page”.
Nieświadomie działałem według takiego klucza w kilku kampaniach, co pozwoliło mi nawet wepchnąć na TOP 1 słowo kluczowe w branży marketingu internetowego ( ͡~ ͜ʖ ͡°).
Dobierałem portale w oparciu o analizę konkurencji jak i naszą Off-site’ową bazę. Z puli publikacji tworzyłem już konkretne koszyki i portale dzieliłem na 3 grupy. Nawet z nazwami grup trafiłem 1:1 do tych Googlowych.

To oryginalny screen z 2021 roku.
Następnie korzystałem z Anchorów w zależności od grupy. Według takiego modelu:
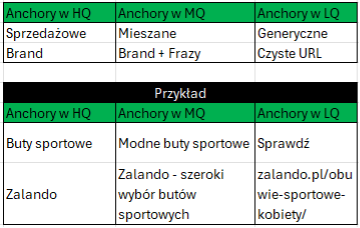
Kampania ta zakończyła się wielkim sukcesem i w ciągu 3 kampanii dobiliśmy TOP 1:
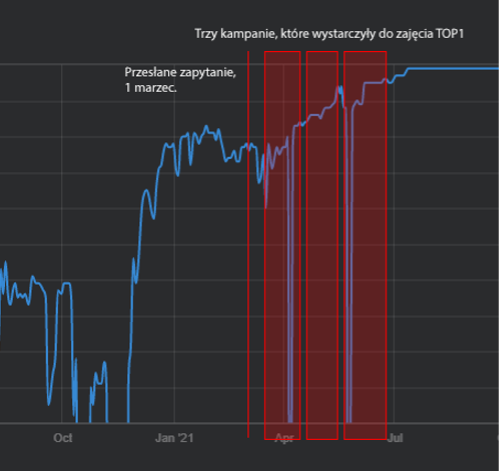
Aż sam byłem zdziwiony skutecznością tej kampanii, a teraz wszystko jest jasne. Case ten dokładnie opisuję na moim szkoleniu z link buildingu.
Google posiada system, który opisuje “typ linka”. Ba, określa nawet czy to “Self Link”, gdy żądanie zostało wykonane z tego samego łącza, co łącze docelowe.
Kary za linki
Po raz kolejny mamy jasną informację - za linki są kary - powtarzam już od dłuższego czasu, że jeden słaby link nam nie zaszkodzi, a dopiero pewna skala zaniedbań może mieć konsekwencje. Kolejne update’y związane ze spamem przesuwają granicę bólu.
Większość kar jest czasowa. Automatycznie nakładana jak i automatycznie ściągana. Wydaje mi się, że mam kilka case’ów, które dokładnie ten proces opisują, ale potrzebuję jeszcze czasu i większą próbkę, żeby wrócić do Was z konkretami. Sprzedam Wam natomiast małą zajawkę.
Mam projekty, które są obojętne na linki. Do czasu. W okolicach update’u są one odblokowywane i wracają do naturalnego cyklu, gdzie link = benefit. Wyraźnie widać okresy w których wybrane strony są po prostu obojętne na działania link buildingowe. Co ciekawe, po odblokowaniu zyskują one na ogólnej widoczności, ale niekoniecznie na zasobach, gdzie mogło dojść do przegięcia z anchorami. Wygląda to tak, jakby sam link finalnie moc przeniósł, ale anchor - który miał stymulować konkretną frazę został wycięty.
Na powyższym mamy wyraźne okienko, w którym strona była zupełnie niezainteresowana linkami. Przypada ono na okres od update’u do update’u. Ten jeden case mógł być po prostu Sandboxem, ale takich przykładów mam więcej.
No właśnie, przy okazji wiemy, że Sandbox istnieje i służy do wyłapywania spamu. Zarazem z moich obserwacji wynika, że strony w “piaskownicy” można linkować, a efekt zobaczymy po wyjściu z Sandboxa.
Podsumowanie
Aspekty dotyczące linków mnie nie zaskoczyły. My to już wszystko wiemy, to dalej te same systemy, tylko na sterydach. Wyciek ten, tak samo jak Yandexowy, potwierdził, że wykorzystywane przez nas metody są skuteczne.
Jedno jest pewne - ostatnie dyskusje o słuszności linków uważam za zamknięte. Odnośniki są wykorzystywane na wielu różnych płaszczyznach, w wielu algorytmach, są cały czas poprawiane, zyskują na dokładności. Pokazuje to jak nierozłączną częścią całego SEO jest link building.
Co ciekawe, nigdzie nie mamy wzmianki o disavoow tool - nie oznacza to natomiast, że system ten nie działa.
Nie ma zbyt wiele informacji o atrybutach linków. Google wspomina kilka razy o UGC, ale w różnych kontekstach (niekoniecznie linków). Ani razu nie wspomina o linkach sponsored. Mamy też pojedyncze wzmianki o nofollow.
Ciekawe jest też, że Google ma systemy, które pomagają mu określić typ linków, nie ma natomiast żadnych danych o tym czy śledzi pozycję linka w tekście (ogólnie jego umiejscowienie).
Michał Masternak
Head of (Off-site) SEO
Praktyk z dekadą doświadczenia w link buildingu. Poprowadziłem tysiące projektów dla największych marek w Polsce.

